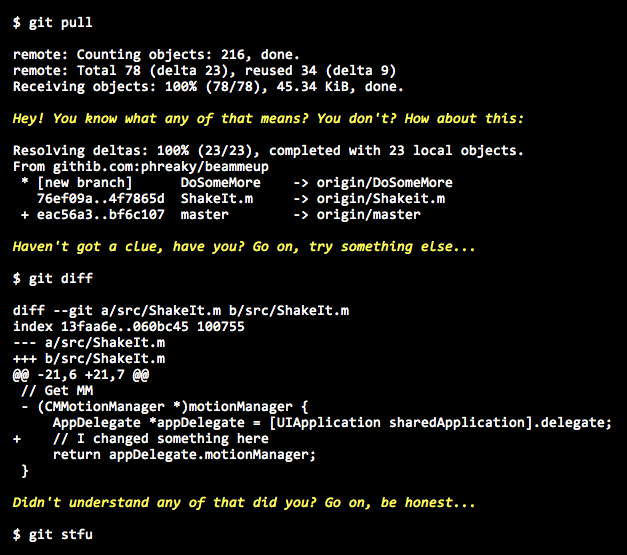
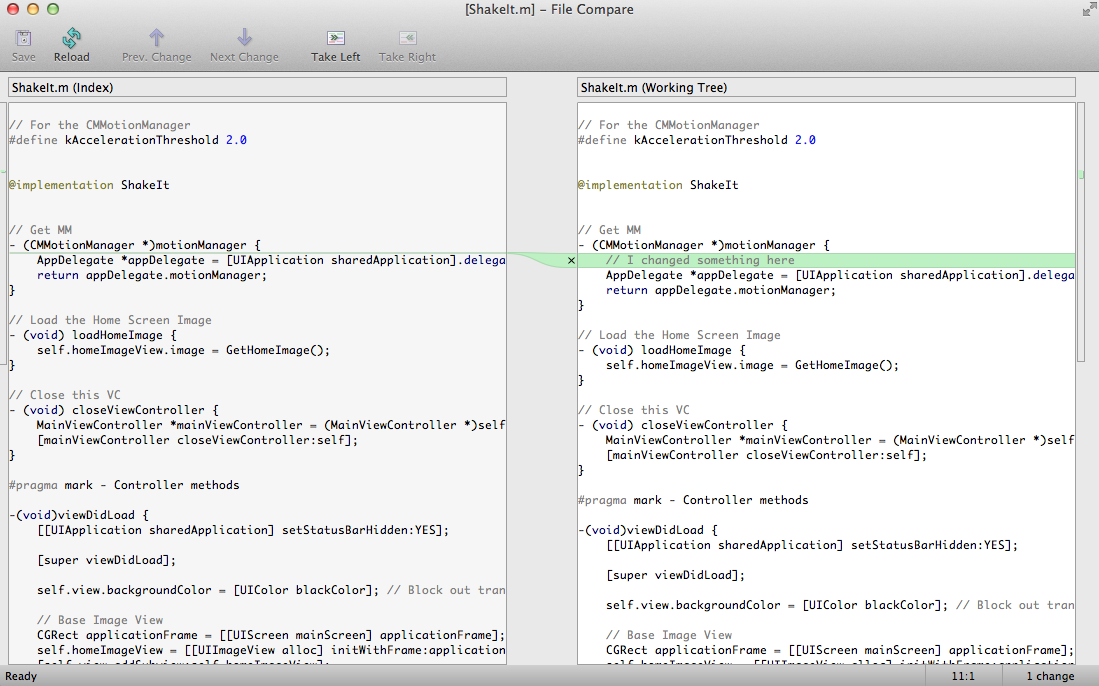
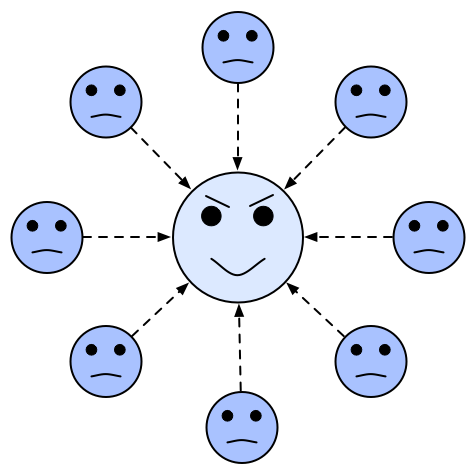
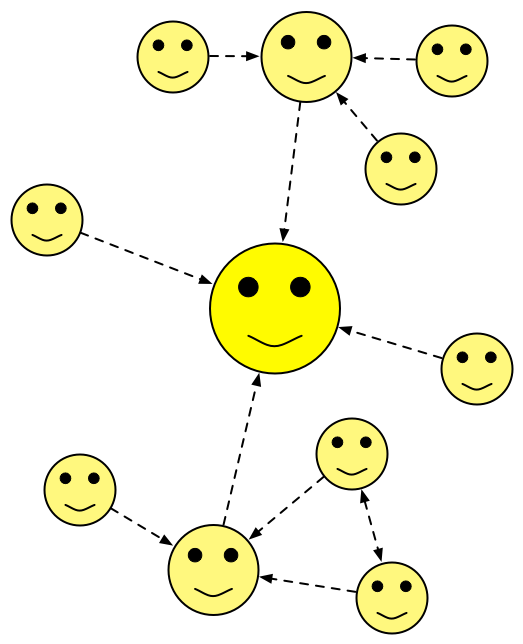
Wired recently ran an article about GitHub – the web service that provides version control management repositories using the Git version control system. What makes this interesting is that, as they point out in the follow-up story, it is a self-referential experiment in version control because, in addition to publishing their story about GitHub on the Wired site, they also published it on GitHub itself. What they did essentially was to eat their own dog food (or put their money where their mouth is, if you prefer) by sharing the text of the article under a Creative Commons licence for anyone to download, edit, modify, translate into another language and then resubmit. An example of crowd-sourcing, right?
Reading the Wired article reminded me of the realisations that occurred to me when I first started to use Git and GitHub. I became aware of the greater potential for distributing and sharing different types of material and the possibilities for social interactivity that it might engender. I found it extraordinary, and still do, that something as geeky as Source Control Management had suddenly become cool, and that there was a buzz around GitHub similar to that coming from Facebook and Twitter.
But first, we need to take a short break for some Git 101…
Git
Git is a distributed or Decentralised Version Control System (DVCS). Prior to Git (and Mercurial, another DVCS) developers managed versions of their shared source code in systems such as CVS and Subversion. Typically, when using these “legacy” systems, a developer downloads any new changes to the shared code-base from the code repository, merges these with their own local changes, edits and adds new code, and then re-submits the new work back to a centralised repository situated on the local network or on a public hosted repository, such as SourceForge. This system ensures that there is a full history of all changes to the code (a record of who did what) and creates “tags” that mark released versions and milestones. The system works somewhat like the revision history used in Wiki software.
But two words immediately stand out here: Code and Centralised. Let’s be honest, these Source Control Management systems were, and still are, typically used by developers for storing their code, whether that be Java code, C++ code, or HTML. And each of those coders is uploading and downloading that code from one single, centralised repository. But what if the server goes down? What if you’re working off-line? What if two people try to upload conflicting changes at the same time? And what if you don’t “do” code?
Enter Linus Torvalds, founder of the Linux operating system. In 2005, after struggling to manage the Linux code-base using an ad hoc system of “patches” sent by users via email or other precarious systems, Torvalds created Git, a version control system designed to ease the burden of source control management and which enables developers to create their own branches or “forks” of the code. These “forks” can remain in the hands of the forker, acting as their own version of Linux, or they may be shared with Torvalds or other developers who would then choose to merge or reject the changes into the main code-base. I recommend that you watch Torvalds describe Git and its genesis in his own inimitable way in this YouTube video of a talk he gave to Google some years ago. At the very least, it’s entertaining.
The beauty of Git is that because the user clones a local copy of the material in the repository on their hard drive they no longer have to be on-line in order to “commit” changes. They can commit as many branches and versions as they like to their local copy and then upload (or “push”) their commits to an on-line repository whenever they happen to be on-line, or not at all. Furthermore, their copy is, in a sense, the repository, being an exact copy of the source. And this is the killer feature, there is no “main” repository, as it’s a distributed system. If a hundred users create a hundred clones of a source repository then there are a hundred separate, and potentially different, versions in existence as each person contributes their own edits and additions. But think about this for a moment: if there are a hundred separate versions of the source material then which one is the “right”, or canonical, one?
For it is written, “…realise the truth. There is no master repository”.
It’s an egalitarian system. Each clone, or copy, of the code can be regarded as the “master” repository. Or not. I can assemble a group of co-workers and we can work collaboratively on our version and merge our changes together and then “push” those changes to yet another group working on the same material. These are self-organising systems.
Having said that, it can be useful to have one nominated de facto repository that hosts the “authoritative” version that can be used for a build, for example if it’s code for an application, or as a starting point for people to clone their own copies. This obviously requires some kind of centralised public presence. Enter GitHub.
GitHub
GitHub is a web-based hosting service for software development projects that use Git. Certainly, Git can be difficult for the non-technical user (and indeed for many avowed techies) and GitHub attempts to make the process a whole lot easier. GitHub’s first tag-line was “Git Hosting: no longer a pain in the ass”.
GitHub provides free (and paid for) facilities to host Git repositories but perhaps more importantly, provides social networking services that aid collaboration and sharing. For example, I can comment on your code, fork your code, ask you to merge my changes into your version (a “pull” request), edit your Wiki, watch your repository and follow users in a similar way to following users on Twitter.
GitHub makes any Git interaction painless, quick and easy. I can browse its collection of repositories, find something I find interesting, click on the “Fork” button and immediately GitHub will create a clone of the repository and add it to my user space. I then get to work on the cloned copy in any way I wish. Using the command line Git is a daunting process for the non-technically inclined, but using GitHub means that you don’t even have to install Git on your computer. Get to work on a project from your iPhone if you like.
It’s been said that GitHub is “Facebook for geeks”, because you can also share snippets of code, text, or anything as a “Gist” – perhaps this feature is akin to a “Twitter for geeks”?
Hold up a moment. Isn’t the idea behind Git that it’s supposed to be decentralised and distributed? Surely GitHub is now functioning as a central repository? Not really. GitHub is just one node amongst potentially many. I myself use three repositories for the code for Archi, a backup on a network drive, one at SourceForge and one at GitHub. These are all mirrors of exactly the same material. GitHub provides visualisation and social tools, and don’t forget the “hub” part of the name. It is centralised, but only in the same way that a common room acts as meeting place for social interaction. You’re free to grab what you want and go. The moment you clone a Git repository you too represent another node in the distributed graph.
Not Only for Developers and Code
As I said earlier, it may seem that Git and GitHub are designed only for developers to manage their code. It turns out that this isn’t the case. What’s interesting is that riding on the back of its cool factor, GitHub is increasingly being used to host and share material that isn’t code. Writers are using it to version and share their novels, musicians to promote their songs and invite remixes, and artists to capture their work-flow.
Writers
As the Wired article mentioned earlier demonstrates, writers are now starting to use Git and GitHub to manage their novels, poems, and articles. Clearly, some writers are finding this invaluable for distributing their work and crowd-sourcing revisions. If they keep versions of their masterpiece in a fine-grained way by committing versions into a Git repository as they progress an interesting archival record is made, as Cory Doctorow points out:
…prior to the computerized era, writers produced a series [of] complete drafts on the way to publications, complete with erasures, annotations, and so on. These are archival gold, since they illuminate the creative process in a way that often reveals the hidden stories behind the books we care about.
And not only that, Doctorow notes that a service such as GitHub can provide you with the means (and the incentive) to publish some or all of your projects to a public repository or to a private site and, furthermore, the publisher can check out the latest revision of an author’s text when it’s time to publish an updated version.
It sounds attractive: push your latest novel to a Git repository, commit your changes, branch off different versions and let your readers and your publisher choose the version they want. Fork that!
Musicians
Durham-based band, the Bristol 7’s, last year released their album, “The Narwhalingus EP” on GitHub under a Creative Commons licence “to see what the world could do with it”. The release, if we can call it that, comprises the final mixes and the individual tracks as MP3 files. The band invites everyone to:
Fork the repo, sing some harmony, steal my guitar solo, or add a Trance beat. Whatever you want to do, just tell us about it, so we can hear what’s become of our baby!
At the time of writing they have nine forks. Actually, ten, since I just forked it. Now where’s that guitar…
Artists
Cory Doctorow has discovered that Mark V of Electric Puppet Theatre is using Git to produce automated “making of” videos of his workflow. V says:
Electric Puppet Theatre is a web comic that I draw in Inkscape, using git for version control. A neat side effect of using git is that I can make a ‘making of’ video for each 24 page issue by playing the git repository through ffmpeg. The linked page contains animations for the first two issues as well as instructions on creating this type of animation (touching on how to make both ogg and youtube-compatible webm animations).
Again, a perfect example of versioning being used to illuminate the creative process and using Git like a playback script.
More Uses
Here’s another very interesting potential use for Git. The Wired article cites the case of Ryan Blair, a technologist with the New York State Senate who wants to see citizens “fork the law”:
[He] thinks it could even give citizens a way to fork the law – proposing their own amendments to elected officials. A tool like GitHub could also make it easier for constituents to track and even voice their opinions on changes to complex legal code. “When you really think about it, a bill is a branch of the law”, he says. “I’m just in love with the idea of a constituent being able to send their state senator a pull request.”
In the world of education, Git could be used to promote the use of Open Educational Resources (OERs) in the class-room. A teacher or lecturer could create their own set of resources under a Creative Commons licence, “push” them to their public GitHub repository and use this as a starting point for distribution, and hopefully attract contributions in order to crowd-source a richer set of materials.
GitHub as a Record of Achievement
Something else occurs to me. If I have all my code publicly available on GitHub with all my interactions, Gists, forks, contributions, interactions and so on, doesn’t this constitute a kind of open record of my personal achievements, competence, abilities and social interaction? It’s common practice for some employers to peruse potential employees’ Facebook pages to discover some juicy bits of background information. Might I not be able to exploit GitHub to show how I’ve been actively engaged in the developer community, or to show off my coding chops?
Git and Me Sitting in a Tree…
Did I mention that I think Git rocks? I was forced to use Git at the start of 2011 when the CVS repository that I relied on at SourceForge became unavailable for several days due to a malicious attack. Ten days later and still with no repository on-line, I vowed never again to be reliant on a single centralised point of failure. This is the beauty of distributed. In fact, Linus Torvalds admits to never backing up his laptop since the work he does is so heavily cloned that his stuff is just “out there”, each user’s copy being a backup in itself.
Even if you are the sole developer/writer/artist/musician on a project don’t assume that you won’t benefit from Git and GitHub. At least you’ll have an archive of past versions and experimental branches to fall back on if things go wrong or you lose your work. For my current project, Archi, I use four Git repositories. Two are deemed to be official or canonical – one at SourceForge and one at Git, one named “experimental” at SourceForge and a local backup. The “experimental” repository allows me to keep experimental work.
Git is good, Git is social, all the cool kids use Git. I can have as many Git repositories as I like, for free, and I don’t have to be on-line when I work. Git, where have you been all my life? And even if you never use Git, who can resist the mascot of GitHub, the mighty Octocat…

Footnote
OK, I admit it. I should have done the obvious and uploaded the text of this post to GitHub…
If you want to find out more about Git I suggest reading Scott Chacon’s useful book “Pro Git”. As for Git tools, I personally don’t use the command line as I like to see what I’m doing. I recommend SmartGit as it’s cross-platform and free for non-commercial usage.
Some resources: